Mathematics is full of problems that we can’t solve. Often we can’t solve them because we lack the tools and ingenuity (such as the Millennium Prize Problems), but there are also times where the solution simply does not exist (even provably so). In the latter case, there are tricks to work around this impossibility and solve the unsolvable: make the problem its own solution!
Over lunch
The idea of turning the tables so that unsolvable problems become their own solution probably sounds either like complete nonsense, or otherwise just completely unhelpful. For instance, consider the question: “Which train goes to the university?” This “trick” would convert this question to the technically correct but completely unhelpful answer: “The train that goes to the university.”
How could this be in any way useful? The answer, while technically correct, does not provide any additional information: the question carries exactly as much information as this answer. What this answer does offer is a placeholder for until a real answer can be provided (or indefinitely, if no such answer is possible). This allows us to study the hypothetical train and its properties. For instance, perhaps the only path to the university goes over a bridge, so this hypothetical train that goes to the university would have to cross this bridge as well. If only a few trains in the city cross this bridge, then this would narrow the search down until you can actually arrive at a more useful answer to the question.
What if there were no trains that go to the university? Then, it would seem like a total waste of time to bother with this hypothetical train that goes to the university, but this sort of void hypothetical can open several new avenues for interesting mathematics. In fact, you likely use this paradigm on a regular basis without even realising.
Imagine yourself in a small farmer’s market, and in your pocket you carry a certain number of coins (for simplicity, let’s just say they’re all loonies; that is, $1.00 each). Needless to say, you can only carry a positive number of coins (or zero coins), and you add and subtract coins according to sales and purchases, respectively. If the vendor offers an item you like for $5.00 and you carry seven coins, then a transaction would result in you having two coins remaining (and the desired item), this following from taking the difference  . This is an example of a problem (transaction) that has a solution.
. This is an example of a problem (transaction) that has a solution.
On the other hand, suppose you had your seven coins, and the vendor offers an item you like for $10.00. Performing the transaction would require taking ten coins from your available seven, but this is impossible! This is a problem that cannot be physically solved, as you cannot take away more than what is present. The best you can do at the moment is give all seven of your coins, but that leaves you $3.00 shy of breaking even. The mathematical solution: make this problem its own solution. This results in you having the desired item, and more than just having no coins, you carry the knowledge that you owe three coins to the vendor. This is more commonly known as “debt”, and is mathematically represented by negative numbers.
In mathematical language: negative numbers are the result of making unsolvable difference problems their own solutions. You can see this in the notation as well:  is shorthand for the unsolvable difference problem
is shorthand for the unsolvable difference problem  .
.
Strictly speaking, negative numbers (aka., debt) do not resolve the unsolvable problem. At the end of your transaction, the vendor still has not made the full $10.00. However, if you later earn more coins, then you can properly resolve this debt by returning to the vendor and paying back the remaining $3.00. Now, the unsolvable transaction is completely resolved in the real world, even though we took a detour through the physically impossible nonsense of negative numbers. This reflects the property that  , and shows how you can work around impossible obstacles and still maintain a consistent system. Granted, the concept of debt requires some sort of honour or enforcement system so that exploitation does not occur, but the field of mathematics has an airtight honour system, so this is no issue on paper. Hopefully this gives a taste for how reinterpreting problems as their own solutions can enable you to push the boundaries of mathematics and provide more tools for solving difficult problems.
, and shows how you can work around impossible obstacles and still maintain a consistent system. Granted, the concept of debt requires some sort of honour or enforcement system so that exploitation does not occur, but the field of mathematics has an airtight honour system, so this is no issue on paper. Hopefully this gives a taste for how reinterpreting problems as their own solutions can enable you to push the boundaries of mathematics and provide more tools for solving difficult problems.
On the bus
The example of negative numbers might seem a bit too “commonplace” of a mathematical concept to demonstrate how bizarre this mathematical technique is: as students, we are introduced to the concept of negative numbers at such an early stage that this physically nonsensical concept has plenty of time to settle in our minds. To some extent, this phenomenon continues the more you study mathematics, with increasingly absurdly impossible objects and structures. I am no philosopher, but this likely plays a part in how “it is a truth universally acknowledged that almost all mathematicians are Platonists, at least when they are actually doing mathematics.” [Fol10]
Rational numbers (i.e., fractions) also fit into this framework, entirely analogous to negative numbers. The problem of dividing a number  of items into
of items into  equal collections can only strictly speaking be solved if divides , in the sense that
equal collections can only strictly speaking be solved if divides , in the sense that  for some number
for some number 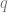 . In this situation, is the solution to this problem, telling you that you can split items into collections where each collection has items. If does not divide , then this problem cannot be solved, so rational numbers come in to make this problem its own solution, saying the answer is just
. In this situation, is the solution to this problem, telling you that you can split items into collections where each collection has items. If does not divide , then this problem cannot be solved, so rational numbers come in to make this problem its own solution, saying the answer is just  .
.
The example of rational numbers also reveals some nuance in this mathematical technique: if you are not careful, making some problems their own solutions might completely destroy your underlying theory. In this case, rational numbers solve these division problems with the exception of dividing by zero: the problem of dividing a number of items into zero groups is left completely unsolved, even if you started with zero items. The reason, essentially, is because we cannot ensure the “uniqueness” of the hypothetical solution to this division problem.
To illustrate, consider the problem of dividing items into two collections. If there were a solution to this problem, then the solution would have to be unique: if I could split items into two collections of , but I could also split them into two groups of  , then
, then  , but if
, but if  , then
, then  . A similar line of reasoning shows that this is true for dividing items into any nonzero number
. A similar line of reasoning shows that this is true for dividing items into any nonzero number  of collections: the key point here is that if
of collections: the key point here is that if  , then . If
, then . If  , then this is no longer true: even if
, then this is no longer true: even if  , we still have
, we still have  , so there is no necessary uniqueness for solutions to division by zero.
, so there is no necessary uniqueness for solutions to division by zero.
People usually summarise this by saying that “you can’t divide by zero,” but it would be more precise to say “you can’t divide by zero uniquely.” This is most apparent when considering the problem of dividing zero items into zero collections: you will notice that any number per collection solves this problem ( items in each collection gives zero total items when you take zero collections, for any value ). Therefore, if you were to assert that this problem had a unique solution, then you would quickly derive that “all numbers are equal” and arrive at a contradiction. If you really insisted on having a theory that allowed for division by zero, you would have to account for this lack of uniqueness somehow: for instance, you would have to accept that it might be possible that  . This added technicality does not provide enough benefit to the theory of rational numbers, so it is omitted.
. This added technicality does not provide enough benefit to the theory of rational numbers, so it is omitted.
There are instances where the lack of uniqueness is accepted: for instance, this happens when solving  (namely, solving for
(namely, solving for  ). We know that a solution is not necessarily unique: if a solution exists, then generally there will be exactly one other solution. For instance,
). We know that a solution is not necessarily unique: if a solution exists, then generally there will be exactly one other solution. For instance,  can be solved both if
can be solved both if  and if
and if 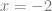 . Therefore, when making the problem its own solution, we accept that the problem only represents one of its solutions. Indeed, we denote the problem (spun as a solution) by
. Therefore, when making the problem its own solution, we accept that the problem only represents one of its solutions. Indeed, we denote the problem (spun as a solution) by  , and we know that another solution is given by
, and we know that another solution is given by  . Since there are generally just these two solutions (except when
. Since there are generally just these two solutions (except when  , where both of these solutions are the same), it’s easy to pick a convention: if
, where both of these solutions are the same), it’s easy to pick a convention: if 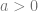 , then
, then  is taken to be the positive solution to . Then, we say that the solutions to are
is taken to be the positive solution to . Then, we say that the solutions to are  . Due to the lack of uniqueness, we then have to accept that it is possible for
. Due to the lack of uniqueness, we then have to accept that it is possible for  (indeed, this always happens for
(indeed, this always happens for  due to our convention).
due to our convention).
Negative numbers (like ), fractions (like 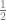 ), radical numbers (like
), radical numbers (like  ), and even real numbers in general (which are also constructed in a similar fashion, as we have seen before)… despite how these concepts really are hard to produce as real physical objects, people are generally okay with their “existence” because the real number line is relatively easy to digest. However, something happens when we try to solve when
), and even real numbers in general (which are also constructed in a similar fashion, as we have seen before)… despite how these concepts really are hard to produce as real physical objects, people are generally okay with their “existence” because the real number line is relatively easy to digest. However, something happens when we try to solve when 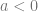 —people are met with how “you can’t take the square root of a negative number.” For simplicity, let’s take
—people are met with how “you can’t take the square root of a negative number.” For simplicity, let’s take  , then you can prove that we cannot solve
, then you can prove that we cannot solve  : a positive multiplied with a positive is positive, so a solution to cannot be positive; but also, a negative multiplied with a negative is positive, so a solution to cannot be negative either. As real numbers are either positive, negative, or zero, and none of these can solve , it follows that the equation cannot be solved at all.
: a positive multiplied with a positive is positive, so a solution to cannot be positive; but also, a negative multiplied with a negative is positive, so a solution to cannot be negative either. As real numbers are either positive, negative, or zero, and none of these can solve , it follows that the equation cannot be solved at all.
However, we can still employ this mathematical technique of making the problem its own solution, and we give this solution “ ” a special name:
” a special name:  , standing for “imaginary unit.” This is honestly such an unfortunate name, because the imaginary unit is no more imaginary than any of the other problems-as-solutions numbers. The number is defined by the property
, standing for “imaginary unit.” This is honestly such an unfortunate name, because the imaginary unit is no more imaginary than any of the other problems-as-solutions numbers. The number is defined by the property  just as is defined by the property that
just as is defined by the property that  . The above proof of the insolubility of should be more accurately stated as: “the problem cannot be solved with real numbers.” What makes this any more different from: “the problem
. The above proof of the insolubility of should be more accurately stated as: “the problem cannot be solved with real numbers.” What makes this any more different from: “the problem  cannot be solved with rational numbers“? Or how about: “the problem
cannot be solved with rational numbers“? Or how about: “the problem  cannot be solved with natural numbers“?
cannot be solved with natural numbers“?
In any case, the introduction of to the theory of real numbers gives us the theory of complex numbers: these are numbers of the form  , where
, where  and
and  are real numbers. Now, it follows (by definition) that the problem can be solved with complex numbers! Now, I have not yet addressed the benefits of introducing imaginary and complex numbers: what does having a non-real number with give us in the real world? Well, the first significant contribution of complex numbers is that not only can you solve the equation , you can actually solve any polynomial equation
are real numbers. Now, it follows (by definition) that the problem can be solved with complex numbers! Now, I have not yet addressed the benefits of introducing imaginary and complex numbers: what does having a non-real number with give us in the real world? Well, the first significant contribution of complex numbers is that not only can you solve the equation , you can actually solve any polynomial equation  with complex numbers! This is the Fundamental Theorem of Algebra.
with complex numbers! This is the Fundamental Theorem of Algebra.
What the Fundamental Theorem of Algebra implies is that once you have complex numbers, you no longer need to introduce new numbers to solve any other equations of polynomials, so in some sense the generalisations of numbers (from an algebraic point of view) stops here. This also implies that any polynomial  can be completely factored into a product of linear terms:
can be completely factored into a product of linear terms:

for appropriate complex numbers  . (Indeed, this is because if a polynomial
. (Indeed, this is because if a polynomial  has a root —meaning
has a root —meaning  —then we can factor
—then we can factor  for some “smaller”polynomial
for some “smaller”polynomial  , and the Fundamental Theorem of Algebra tells us that all nonconstant polynomials have roots.)
, and the Fundamental Theorem of Algebra tells us that all nonconstant polynomials have roots.)
Let’s see how this can help us in more “real” problems: since polynomials can be factored so “easily” over the complex numbers, this can provide a means to factor real polynomials more easily as well. For an explicit example: consider the problem of factoring  as much as possible over the real numbers. With enough experience playing around with algebraic expressions, you might be able to guess its factors, but with familiarity with complex numbers, you could find all four roots of this polynomial. Indeed, the roots of are
as much as possible over the real numbers. With enough experience playing around with algebraic expressions, you might be able to guess its factors, but with familiarity with complex numbers, you could find all four roots of this polynomial. Indeed, the roots of are  ,
,  ,
,  ,
,  , and so the factorisation of this polynomial over the complex numbers is
, and so the factorisation of this polynomial over the complex numbers is

From here, you can multiply factors together until you get (irreducible) real polynomials. In particular,  and
and  , and so this gives us the complete factorisation of to be
, and so this gives us the complete factorisation of to be

You can use the quadratic formula (and avoid complex numbers altogether) to check that this factorisation is complete over the real numbers. More generally, if  is a root of a real polynomial , then so is
is a root of a real polynomial , then so is  . If
. If  , then these two roots pair up to give you an irreducible quadratic factor of . This shows that the Fundamental Theorem of Algebra implies that all real polynomials factor into a product of linear and quadratic terms.
, then these two roots pair up to give you an irreducible quadratic factor of . This shows that the Fundamental Theorem of Algebra implies that all real polynomials factor into a product of linear and quadratic terms.
Perhaps one of the most canonical (and somewhat more modern) examples of making the problem its own solution is the theory of distributions, with the famous example being the Dirac delta  . The delta “function” is characterised by the property that
. The delta “function” is characterised by the property that  for any (nice) function
for any (nice) function  . It is, of course, impossible for a genuine function to meet this requirement: using various , you can show that such a function would have to satisfy
. It is, of course, impossible for a genuine function to meet this requirement: using various , you can show that such a function would have to satisfy  for almost all
for almost all  , but integrating against a function that is zero almost everywhere must always yield zero (in particular, this would force
, but integrating against a function that is zero almost everywhere must always yield zero (in particular, this would force  when it should be equal to one).
when it should be equal to one).
The physics-y workaround to this impossibility is to say that  is so infinitely large that it carries the entire weight of the function so that the integral works out to one. A probabilistic interpretation of is of “absolute certainty” in the following sense. If you had a particle that lived on the real number line, and you were unsure of where it existed, then you would have a probability distribution (more specifically, a probability density function) reflecting where the particle could be. More specifically, would allow us to compute the probability that the particle lived between and , with the probability being
is so infinitely large that it carries the entire weight of the function so that the integral works out to one. A probabilistic interpretation of is of “absolute certainty” in the following sense. If you had a particle that lived on the real number line, and you were unsure of where it existed, then you would have a probability distribution (more specifically, a probability density function) reflecting where the particle could be. More specifically, would allow us to compute the probability that the particle lived between and , with the probability being  . (Note that since the particle must be somewhere, it follows that
. (Note that since the particle must be somewhere, it follows that  .) Under this interpretation, would be the probability density “function” of a particle we knew 100% lived at the origin. Hence, all of the density would have to rest on .
.) Under this interpretation, would be the probability density “function” of a particle we knew 100% lived at the origin. Hence, all of the density would have to rest on .
Neither of these are mathematically rigorous incarnations of (since it provably cannot exist), but distributions come into play as a generalisation of functions that make the desired property of the very definition of . Loosely speaking, a distribution 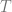 assigns to every nice function a number
assigns to every nice function a number  . The distribution represents some hypothetical (probably non-existing) “function”
. The distribution represents some hypothetical (probably non-existing) “function”  , where the number is the result of the hypothetical integral
, where the number is the result of the hypothetical integral  . While may not exist, definitely does. For example, the Dirac delta is realised as the distribution which assigns each (nice) function to
. While may not exist, definitely does. For example, the Dirac delta is realised as the distribution which assigns each (nice) function to  —this is precisely the desired property of . Since the Dirac delta should only ever make appearances inside an integral sign, this formalism with distributions then allows us to work consistently with the Dirac delta in analysis, despite the impossibility that it exists.
—this is precisely the desired property of . Since the Dirac delta should only ever make appearances inside an integral sign, this formalism with distributions then allows us to work consistently with the Dirac delta in analysis, despite the impossibility that it exists.
In the lounge
I first heard this slogan of making (unsolvable) problems their own solutions in a course with Kai Behrend on algebraic stacks [Beh20, page 32]. Specifically, he was referring to the challenge of trying to continuously parametrise triangles up to similarity in a “good” way. For example, one such parameter space would be the subspace  of points
of points  such that
such that  and
and  : every triangle is similar to one of perimeter
: every triangle is similar to one of perimeter  , in which case
, in which case 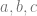 label the side lengths (in order of magnitude). If
label the side lengths (in order of magnitude). If  is the space of triangles modulo similarity, then the parametrisation is precisely the map
is the space of triangles modulo similarity, then the parametrisation is precisely the map  that sends
that sends  to the (similarity class of the) triangle with sides
to the (similarity class of the) triangle with sides  .
.
This seemingly innocent problem becomes much more challenging when you want the parametrisation to be particularly “good:” can we find a continuous parametrisation  which is universal in the sense that any other continuous parametrisation
which is universal in the sense that any other continuous parametrisation  of triangles can be obtained from
of triangles can be obtained from  via some (unique) map
via some (unique) map  via
via  ? With this notion of universality, is actually sufficient!
? With this notion of universality, is actually sufficient!
However, is not entirely satisfactory: while can parametrise triangles, can it also parametrise continuous families of triangles? Roughly speaking, this is the “moduli problem” posed by  , and a solution
, and a solution  would be called the fine moduli space of . To elaborate a bit: universality ensures that if I have a continuous family
would be called the fine moduli space of . To elaborate a bit: universality ensures that if I have a continuous family  of triangles (parametrised by
of triangles (parametrised by ![t\in[0,1]](https://s0.wp.com/latex.php?latex=t%5Cin%5B0%2C1%5D&bg=ffffff&fg=666666&s=0&c=20201002) ), there is a (unique) continuous family of points in the fine moduli space
), there is a (unique) continuous family of points in the fine moduli space 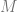 —given by a function
—given by a function ![f:[0,1]\to M](https://s0.wp.com/latex.php?latex=f%3A%5B0%2C1%5D%5Cto+M&bg=ffffff&fg=666666&s=0&c=20201002) —such that
—such that  is in the similarity class of for every ; however, to be a fine moduli space, this has to somehow completely classify the continuous families (i.e., if and
is in the similarity class of for every ; however, to be a fine moduli space, this has to somehow completely classify the continuous families (i.e., if and  are families of triangles that both come from the same continuous family , then the families should be isomorphic).
are families of triangles that both come from the same continuous family , then the families should be isomorphic).
What makes this difficult for to achieve is the fact that the parametrisation also gives the triangles’ sides labels (via ). This is generally not an issue, but what if is the equilateral triangle with perimeter , rotated  radians? These are all similar to each other, so the parametrisation should be trivial, and indeed the unique pullback
radians? These are all similar to each other, so the parametrisation should be trivial, and indeed the unique pullback ![f:[0,1]\to\tilde M](https://s0.wp.com/latex.php?latex=f%3A%5B0%2C1%5D%5Cto%5Ctilde+M&bg=ffffff&fg=666666&s=0&c=20201002) for this family just labels all the same way with
for this family just labels all the same way with  . However, this labelling seems more appropriate for the “continuous family” of equilateral triangles where is the exact same equilateral triangle for all . The two families and are undeniably different (the former is an arguably nontrivial “cycle” of triangles that cannot have its sides consistently and continuously labelled by the letters , whereas the latter does not have this issue), but induce the same pullback . This highlights the failure of to be a fine moduli space for triangles up to similarity, and also exposes a source of failure: symmetries of a triangle. The family would not have been possible if the triangle were not equilateral.
. However, this labelling seems more appropriate for the “continuous family” of equilateral triangles where is the exact same equilateral triangle for all . The two families and are undeniably different (the former is an arguably nontrivial “cycle” of triangles that cannot have its sides consistently and continuously labelled by the letters , whereas the latter does not have this issue), but induce the same pullback . This highlights the failure of to be a fine moduli space for triangles up to similarity, and also exposes a source of failure: symmetries of a triangle. The family would not have been possible if the triangle were not equilateral.
Indeed, this is an obstruction to solving general moduli problems: a slogan from the nLab states that “a type of objects that has nontrivial automorphisms cannot have a fine moduli space.” In his notes, Behrend shows that after restricting to scalene triangles (i.e., triangles with no symmetries), we can indeed define a fine moduli space (and thus solve the moduli problem). However, restricting to families of mathematical objects with no symmetries is generally too much to ask for, and calls for a workaround when a fine moduli space provably does not exist. This is where this paradigm of making the problem its own solution comes into play, in the form of moduli stacks. The trick, roughly, is to simultaneously take all solutions to the moduli problem collectively, and call this the “best” solution. The technical grief one usually experiences when trying to work with stacks then comes from trying to make this trick useful; that is, make the moduli stack “space-like.”
Maybe it’s clear from reading my ramblings up there, but I don’t really know what I’m talking about when I talk about stacks (unless I am just speaking of them as 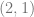 -sheaves, in which case I now have a better idea). There are also other examples that I might be able to provide with competent commentary.
-sheaves, in which case I now have a better idea). There are also other examples that I might be able to provide with competent commentary.
For instance, I have already talked at some length about the problem: given a (commutative, unital) ring 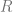 , is there a space (of a topological or algebraic nature) whose ring of regular functions is given by ? For most rings, there is no true solution to this problem. Applying this paradigm of making problems their own solutions yields the theory of schemes: simply declare the ring to be (dual to) the canonical “space” whose ring of regular functions is . For clarity, denote the “space” by
, is there a space (of a topological or algebraic nature) whose ring of regular functions is given by ? For most rings, there is no true solution to this problem. Applying this paradigm of making problems their own solutions yields the theory of schemes: simply declare the ring to be (dual to) the canonical “space” whose ring of regular functions is . For clarity, denote the “space” by  and call it the affine scheme associated to . The challenge is then to make this useful (and perhaps push the limits of this analogy that elements of are “functions” on ). For instance, this trick is given some meat by declaring the points of to be the prime ideals of , and then any
and call it the affine scheme associated to . The challenge is then to make this useful (and perhaps push the limits of this analogy that elements of are “functions” on ). For instance, this trick is given some meat by declaring the points of to be the prime ideals of , and then any  becomes a function of prime ideals, whose value at
becomes a function of prime ideals, whose value at  is given by
is given by  .
.
In higher category theory, this trick has also been employed especially to produce good models of  -categories. In this case, it’s not so much that higher categories cannot be “solved” (i.e., axiomatised), but rather that such an axiomatisation is extremely unwieldy and impractical. That being said, the moral and intention of higher categories are clear, and there are several “litmus tests” that a proper theory of higher categories should satisfy. Therefore, the trick of making problems into their own solutions materialises in this case by taking (some of) these litmus tests to be the definition.
-categories. In this case, it’s not so much that higher categories cannot be “solved” (i.e., axiomatised), but rather that such an axiomatisation is extremely unwieldy and impractical. That being said, the moral and intention of higher categories are clear, and there are several “litmus tests” that a proper theory of higher categories should satisfy. Therefore, the trick of making problems into their own solutions materialises in this case by taking (some of) these litmus tests to be the definition.
In particular, one of the main litmus tests that can be easily flipped into a definition is the Homotopy Hypothesis, which stipulates that higher groupoids should correspond to topological spaces up to weak homotopy. This generalises the phenomenon in ordinary category theory that groupoids correspond to (homotopy 1-types of) topological spaces, with a space 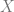 corresponding to its fundamental groupoid
corresponding to its fundamental groupoid  , and a groupoid
, and a groupoid  corresponding to its Eilenberg-Mac Lane space
corresponding to its Eilenberg-Mac Lane space  . Therefore, a handful of models employ the Homotopy Hypothesis to define
. Therefore, a handful of models employ the Homotopy Hypothesis to define 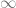 -groupoids to be topological spaces (considered up to weak homotopy). Then, -categories—being weakly enriched in -groupoids—can be defined as categories enriched in spaces. Even the popular model of quasicategories builds off this trick (after taking a detour through the homotopy theory of simplicial sets).
-groupoids to be topological spaces (considered up to weak homotopy). Then, -categories—being weakly enriched in -groupoids—can be defined as categories enriched in spaces. Even the popular model of quasicategories builds off this trick (after taking a detour through the homotopy theory of simplicial sets).
Despite how common this paradigm occurs in mathematics, I still find it difficult sometimes to accept (and internalise) how the problems do indeed serve as solutions. For instance, it took me an embarrassing amount of time (and a bit of help) before I could really digest how a simplicial set with the right lifting property against inner horn inclusions (aka., a quasicategory) can really be thought of as a homotopy-coherent category and thus an -category. Perhaps the difficulty (or lack of will) when trying to digest these absurd abstractions also generally determines for developing mathematicians how deep and how abstract they are willing to go before settling in an area of mathematics to pursue their studies in.

2 thoughts on “Making unsolvable problems their own solutions”