- The derivative
- The derivative, in many variables
- “The Earth isn’t flat, but it’s close”
- The derivative of the Earth
The sun is shining, and the breeze entices the leaves of your grand apple tree to sing a joyous tune. You sit at the edge of the balcony and watch the tree branches dance to the rhythm of their song. Amidst the poetry, an apple is fed up with the palpable pretentiousness, and detaches himself from the scene, awaiting the soothing embrace of the grass blades beneath.
As the apple of your eye descends to the earth, you wonder… how fast did the apple fall after one second?
At first, this question seems entirely reasonable… until you realise it doesn’t really make sense. The speed of a car, for instance, is usually measured in kilometres per hour (that is, assuming you live in a country that uses metric), which tells you how many kilometres your vehicle would cover if you maintained the given speed for exactly one hour. In order to determine the (average) velocity of an object—such as a car, or your dear apple—you need to calculate

In fancier (i.e., mathematical and physical) notation, this would be written as

In particular, the calculation of velocity requires sampling at two separate times. Therefore, it’s rather nonsensical to ask for how quickly an apple is moving at a single specific time; that’s like taking a snapshot of the falling apple and trying to use this to determine its velocity.
This doesn’t deter you, though, since there still seems to be some merit behind the concept of an “instantaneous velocity.” So, you try to approximate what this quantity should be. You try sampling the position of the apple every 

To estimate the instantaneous velocity at time 

These tell you that what would be the instantaneous velocity must have been somewhere near 7.3 and 12.3 metres per second. To improve the approximation, you sample more frequently, thus making 
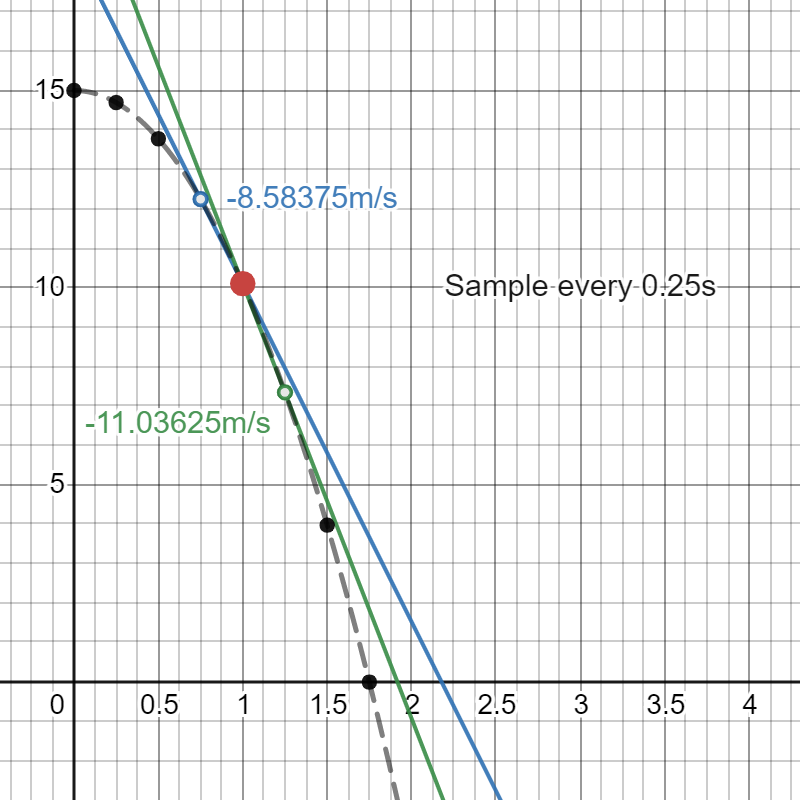





(You can experiment with this yourself on Desmos.) As
More precisely: if the position (say, of your apple) is given as a function 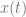

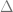

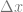

In mathematical language, the value 

The derivative
Moving away from physics, you realise that you can do the same thing with other functions 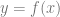


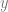



With the ideas behind instantaneous velocities, you realise that you can begin to make sense of instantaneous slopes of a function: if you have a function 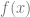

The instantaneous slope at a point
However, you quickly realise that not all functions have derivatives. For example, the absolute value function

does not have a well-defined derivative at zero (sampling right before zero gives you a slope of 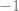
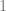
In other words, if you look closely enough at the point 
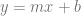

What this means more concretely is that when you’re close to a point

which is then called the linear approximation of

where 

Note. If the change in 



If you were to graph the linear approximation of a function (e.g., for the position of a falling apple), you get a better idea what this line really is:

For a sufficiently smooth function, the linear approximation gives us the line that lies tangent to our function at the point; that is, the line that seems to just “touch” our function without blatantly impaling it. By looking at the graph, you can also see that the linear approximation is actually quite good at estimating differentiable functions! This has great consequences for simplifying calculation and analysis:


The concept of tangents (like the above) is a way of formalising “flattening” shapes while retaining as much information as possible. This is the idea underlying why you can use a flat, two-dimensional map of a city and reliably eyeball how distances, angles, and sizes compare between different locations, despite the general spherical shape of the Earth: a city is so small compared to the whole Earth that a map—which is exactly a (scaled-down) linear approximation of the true city—barely differs in geometry from the city itself.
For the record, the same cannot be said about any flat, two-dimensional map of the western hemisphere, by the Theorema Egregium.

This being said, we haven’t yet established the mathematics necessary to talk about tangent planes of the Earth. As a first step, we would need to establish a theory of higher-dimensional differentiable functions.
The derivative, in many variables
For example, let’s consider a function 

Therefore, declare 

Based off of the same discussion in the one-dimensional case, it’s natural to expect that the “derivative” of 
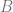
Understanding one-dimensional derivatives turns out to be sufficient for determining what the coefficients 



for the function 
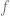

Entirely analogously, the coefficient 

In summary, a two-dimensional differentiable function admits a planar approximation (which is actually still just called a linear approximation) of the form

Note. By taking the changes in 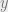

The two-dimensional vector which collects these partial derivatives is called the gradient of 
The story is exactly the same for higher-dimensional functions 






Using Sigma notation, this equation can be written more briefly as

and the gradient (“derivative”) of 

It’s more useful to think of 
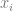


However, with the gradient vector of a differentiable function, you can compute the directional derivative more simply as the dot product 
*Technical remark. The direction for a directional derivative should be a unit vector. However, if 

A related advantage of taking the gradient to be a (row) vector rather than just a list of numbers is that it allows us to rewrite the linear approximation of

showing how the multivariable story is very much the same as the one-dimensional story we started with.
Remark. I am aware of the unfortunate notation clash. When I write 
Moreover, this presentation of the linear approximation suggests that we shouldn’t think of the derivative of a function as a mere number, but rather as a linear transformation. This becomes particularly handy when you try to generalise the derivative further to handle a multivariable vector-valued function 



Equivalently (if you like to bring limits into the story), the total derivative is the unique operator such that

Write 






which is called the Jacobian of
This more general theory of differential calculus is quite versatile, and allows us to compute tangents and linear approximations for many things. For instance, we can model the hills or mountains with a smooth function 

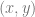


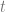
However, we still haven’t quite developed enough mathematics to talk about the surface of the Earth. The issue with smooth geometric shapes—such as ellipses, spheres, tori (i.e., doughnuts), or any kind of blob existing in higher-dimensional space—is that they are typically not graphs of functions. For example, a unit circle centred at the origin has two 


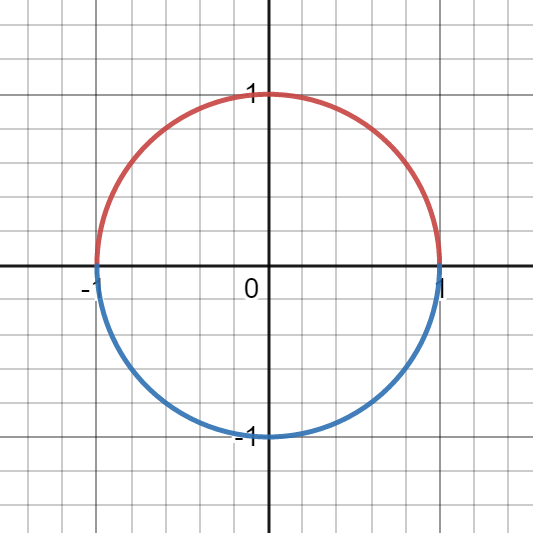
This almost seems to solve the issue: you can then use differential calculus on the two functions to compute tangent lines and the whole works. However, this isn’t perfect: even just on the circle presented above, we cannot use the function decomposition to compute the tangent lines where 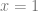

“The Earth isn’t flat, but it’s close”
The idea is so close to working, though, so the idea is to modify this kind of deconstruction so that it doesn’t depend on how we draw our geometric shape in Euclidean space (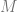
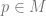

For example, consider the unit circle again: this should be a smooth 1-manifold, so consider the point at the north pole. The figure below shows how to smoothly transform the upper semicircle into a straight line:

These smooth transformations allow you to define a local coordinate system on your manifold; that is, when you’re near a point 
Using the map analogy, you can equivalently describe a smooth
Formal definition (skippable). A smooth 
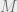




Let 




The atlas provides us with a local coordinate system: for a point 






Now, suppose we have a smooth function 






Therefore, we can reuse the theory already developed for derivatives of multivariable functions to compute the total derivative of 
Remember that we first interpreted the total derivative of an ordinary multivariable function at a point as the best linear approximation of the function at the chosen point. This made a lot of sense in Euclidean space
The atlas on a manifold
*Technical remark. The compass directions don’t actually make sense at the north and south poles, but they work as local coordinates everywhere else. Just use it as a fairly robust analogy of what local coordinates are—you can’t define a smoothly varying local coordinate system on 
The problem is that the compass directions aren’t actually supposed to curve with the Earth: they should instead span a flat plane that shoots off the Earth from your reference point:

As you can see, what we really want is to look at the tangent spaces on our manifold! The local coordinates are not directly part of the tangent space since they are glued to the manifold itself and stop making sense if you move too far away from your starting point (because they’re local coordinates). How, then, do we escape the confines of our manifold?
The derivative of the Earth
Well, we do it by running. Imagine you’re running in a straight line on Earth, and then suddenly gravity “turns off.” What happens? You’ll start shooting off in the direction you were running (i.e., in the direction of your velocity vector): this direction sits tangent to the Earth! This is exactly how the tangent space on a manifold is defined: the tangent space at a point 
What does this mean more mathematically? Let’s say 
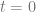



Just as in the beginning of this story, velocity is given as the derivative of position with respect to time, so the instantaneous velocity vector for

It follows that all tangent spaces of an 
Let’s apply this to the 2-manifold we call Earth. The tangent space is spanned by the velocity vectors 

This technically completes the story of finding tangents on a manifold, but this sort of definition of the tangent space is… clunky. First, if given a tangent vector, it’s difficult to recover a path whose instantaneous velocity is given by this vector. Secondly, this definition seems to depend on our choice of local coordinates. Not every manifold has a natural or obvious local coordinate system at every point, so it would be better if the tangent space could be defined independently of any choice of coordinates.
To find a better definition, we work backwards: let’s suppose 

If we think locally, a smooth function 



(This follows from the chain rule.) Therefore, we can redefine the tangent space 


Remark (skippable). The more precise definition of the vectors of the tangent space—that is, the more precise definition of “directional derivatives”—at 

In general, then, a 

Leibniz’s law is enough to imply that derivations only care about how 

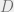



This shows that all 
Let’s remember what we were trying to do: we had a smooth function 

If you pick a local coordinate system 




While perhaps not the easiest to see in this form, this is really just the chain rule back at it again. However, we don’t want this to be the definition of the total derivative of a smooth function of manifolds at a point: once again, this definition depends on our choice of local coordinates! Now that we have a coordinate-free definition of the tangent space, we should be able to find a coordinate-free definition of the derivative.
The elements of our tangent space 




In particular, we can see that the derivative of 
In particular, if you choose a cardinal direction 

which is exactly the same as what we had before: giving more meaning to
as just being an analogue of the chain rule.
Remark (skippable). The above computation uses the fact that 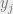



Excellent: after all this work, we have finally formalised how to take derivatives on (and of) Earth!
There’s just one thing left that seemed to get lost when we left the world of one-variable calculus: if we had a smooth function 

Well, the idea is to “bundle up” our tangent spaces and build a manifold of tangent vectors, so that the tangent spaces 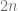



We get a canonical projection map 



Formal definition (skippable). A (real) vector bundle of rank 
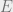
- a smooth projection map
such that the fibre
is a
- an open neighbourhood
and a homeomorphism
called a local trivialisation. This is required to be compatible with the projection and the vector space fibres: for every
,
for all
is a linear isomorphism

The tangent bundle is then the vector bundle 





MSE]).

Good job in explaining this. There’s one more definition of the tangent space at : the dual of
: the dual of  where
where  is the maximal ideal of (germs of) functions vanishing at
is the maximal ideal of (germs of) functions vanishing at  . The analogue of this one’s pretty useful in algebraic geometry. Make a post on that subject!
. The analogue of this one’s pretty useful in algebraic geometry. Make a post on that subject!
LikeLiked by 1 person
Thanks! I was thinking of doing a post on cotangent spaces whenever I find time, and I’ll definitely talk about when I get there. 🙂
when I get there. 🙂
LikeLike